I’ve worked with deploy systems in the past that have a prominent “rollback” button, or a console incantation with the same effect. The presence of one of these is reassuring, in that you can imagine that if something goes wrong you can quickly get back to safety by undoing your last change.
But the rollback button is a lie. You can’t have a rollback button that’s safe when you’re deploying a running system.
The majestic bison is insouciant when monopolizing the push queue, stuck in a debug loop, to the annoyance of his colleagues.
The Old Version does not Exist
The fundamental problem with rolling back to an old version is that web applications are not self-contained, and therefore they do not have versions. They have a current state. The state consists of the application code and everything that it interacts with. Databases, caches, browsers, and concurrently-running copies of itself.
What they don’t tell you in school is the percentage of your life as a working programmer that will be spent dealing with the “plus” sign.
You can roll back the SHA the webservers are running, but you can’t roll back what they’ve inflicted on everything else in the system. Well, not without a time machine. If you have a time machine, please use the time machine. Otherwise, the remediation has to occur in the direction of the future.
A Demonstration
Contriving an example of a fault that can’t be rolled back is trivial. We can do this by starting with a python script that emulates a simple read-through cache:
# version1.py
frompymemcache.client.baseimportClientc=Client(('localhost',11211))db={'a':1}defread_through(k):v=c.get(k)ifnotv:# let’s pretend this reads from the database.
v=db[k]c.set(k,v)returnint(v)print('value: %d'%read_through('a'))
We can verify that this works fine:
$ python version1.py
value: 1
Now let’s consider the case of pushing some bad code over top of it. Here’s an updated version:
# version1.py
frompymemcache.client.baseimportClientc=Client(('localhost',11211))db={'a':1}defread_through(k):v=c.get(k)ifnotv:# let’s pretend this reads from the database.
v=db[k]c.set(k,v)returnint(v)defwrite_through(k,val):c.set(k,val)db[k]=int(val)# mess up the cache lol
write_through('a','x')print('value: %d'%read_through('a'))
That corrupts the cache, and promptly breaks:
$ python version2.py
ValueError: invalid literal for int() with base 10: ’x’
At this point, red sirens are going off all over the office and support reps are sprinting in the direction of our desks. So we hit the rollback button, and:
$ python version1.py
ValueError: invalid literal for int() with base 10: b’x’
Oh no! It’s still broken! We can’t resolve this problem by rolling back. We’re lucky that in this case, nothing has been made the worse. But that is also a possibility. There’s no guarantee that the path from v1 to v2 and then back to v1 isn’t actively destructive.
A working website can eventually be resurrected by writing some new code to cope with the broken data.
defread_through(k):v=c.get(k)ifnotv:# let’s pretend this reads from the database.
v=db[k]c.set(k,v)try:returnint(v)exceptValueError:# n.b. we screwed up some of the cached values on $DATE,
# this remediates
v=db[k]c.set(k,v)returnint(v)
You might dispute the plausibility of a mistake as transparently daft as this. But in my career I’ve carried out conceptually similar acts of cache destruction many times. I’m not saying I’m a great programmer. But then again maybe you aren’t, either.
A Sharp Knife, Whose Handle is also a Knife
Adding a rollback button is not a neutral design choice. It affects the code that gets pushed. If developers incorrectly believe that their mistakes can be quickly reversed, they will tend to take more foolish risks. It might be hard to talk them out of it.
Mounting a rollback button within easy reach (as opposed to git revert, which you probably have to google) means that it’s more likely to be pressed carelessly in an emergency. Panic buttons are for when you’re panicking.
Practice Small Corrections
Pushbutton rollback is a bad idea. The only sensible thing to do is change the way we organize our code for deployment.
Push “dark” code. You should be deploying code behind a disabled feature flag that will not be invoked. It’s relatively easy to visually inspect an if statement for correctness and check that a flag is disabled.
Ramp up invocations of new code. Breaking requests without a quick rollback path is bad. But it’s much worse to break 100% of requests than it is to break 1% of requests. If we ramp up new code gradually, we can often contain the scope of the damage.
Maintain off switches. In the event that a complicated remediation is required, we’re in a stronger position if we can disable broken features while we work on them in relative calm.
Roll forward. Production pushes will include many commits, all of which need to be evaluated for reversibility when a complete rollback is proposed. Reverting smaller diffs as a roll-forward is more verifiable.
Complete deployment rollbacks are high-G maneuvers. The implications of initiating one given a nontrivial set of changes are impossible to reason about. You may decide that one is called for, but you should do this as a last resort.
Building a web application is a young and poorly-understood activity. Toolchains for building code in general are widely available, relatively older, and they also happen to be closest at hand when you’re getting started. The tendency, then, is to pick some command line tools and work forwards from their affordances.
Git provides methods for coping with every merge problem conceivable. It also gives us support for arbitrarily complicated branching and tagging schemes. Many people reasonably conclude that it makes sense to use those features all the time.
I found myself in a dark wood, where the straight way was lost. The good lord would not have given me this 25 ton hydraulic splitter if I weren’t meant to cut up some logs.
I’ll make the case for one practice that works very well operationally: deploying small units of code to production on a regular basis. I think that your deploys should be measured in dozens of lines of code rather than hundreds. You’ll find that taking this as a fixed point requires only relatively simple uses of revision control.
Ship small diffs, and stand a snowball’s chance of inspecting them for correctness.
Your last chance to avoid broken code in production is just before you push it, and to that end many teams think it’s a good idea to have standard-ish code reviews. This isn’t wrong, but return on effort diminishes.
Submitting hundreds of lines of code for review is a large commitment. It encourages sunk cost thinking and entrenchment. Reviews for large diffs are closed with a single “lgtm,” or miss big-picture problems for the weeds. Even the strongest cultures have reviews that devolve into Maoist struggle sessions about whitespace.
Your tormentors will demand baffling, seemingly-trivial concessions.
Looking at a dozen lines for mistakes is the sort of activity that is reasonably effective without being a burden. This will not prevent all problems, or even fail to create any new ones. But as a process it is a mindful balance between the possible and the practical.
Ship small diffs, because code isn’t correct until it’s running production.
The senior developer’s conditioned emotional response to a large deploy diff is abject terror. This is an instinctive understanding of a simple relationship.
Quick, find the red one
Every line of code has some probability of having an undetected flaw that will be seen in production. Process can affect that probability, but it cannot make it zero. Large diffs contain many lines, and therefore have a high probability of breaking when given real data and real traffic.
In online systems, you have to ship code to prove that it works.
Ship small diffs, because the last thing you changed is probably setting those fires.
We cannot prevent all production problems. They will happen. And when they do, we’re better off when we’ve been pushing small changesets.
Many serious production bugs will make themselves evident as soon as they’re pushed out. If a new database query on your biggest page is missing an index, you will probably be alerted quickly. When this happens, it is reasonable to assume that the last deploy contains the flaw.
Oops
At other times, you’ll want to debug a small but persistent problem that’s been going on for a while. The key pieces of information useful to solving such a mystery are when the problem first appeared, and what was changed around that time.
In both of these scenarios, the debugger is presented with a diff. Finding the problem in the diff is similar to code review, but worse. It’s a code review performed under duress. So the time to recover from problems in production will tend to be proportional to the size of the diffs that you’re releasing.
Taking Small Diffs Seriously
Human frailty limits the efficacy of code review for prophylactic purposes. Problems in releases are inevitable, and scale with the amount of code released. The time to debug problems is a function of (among other things) the volume of stuff to debug.
This isn’t a complicated list of precepts. But taking them to heart leads you to some interesting conclusions.
Branches have inertia, and this is bad. I tell people that it’s fine with me if working in a branch helps them, as long as I’m not ever able to tell for sure that they’re doing it. It’s easier to double down on a branch than it is to merge and deploy, and developers fall into this tiger trap all the time.
Lightweight manipulation of source code is fine. PR’s of GitHub branches are great. But git diff | gist -optdiff also works reasonably if we are talking about a dozen lines of code.
You don’t need elaborate Git release rituals. Ceremony such as tagging releases gets to feel like a waste of time once you are releasing many times per day.
Your real problem is releasing frequently. Limiting the amount of code you push is going to block progress, unless you can simultaneously increase the rate of pushing code. This is not as easy as it sounds, and it will shift the focus of your developer tooling budget in the direction of software built with this goal in mind.
That is not an exhaustive list. Starting from operations and working backwards has lead us to critically examine what we do in development, and this is a good thing.
Note: This was a post for Skyliner, which was a startup I co-founded in 2016. The post is recreated here since it makes some good points and was reasonably popular. But be advised the startup it describes is now defunct (we sold ourselves to Mailchimp in 2017).
I’ve been around long enough to see production releases done a few different ways.
My first tech job began back when delivering software over the internet wasn’t quite normal, yet. Deployments happened roughly every 12 to 18 months, and they were unmitigated disasters that stretched out for weeks.
When I got to Etsy in 2007, deploys happened a bit more often. But they were still arcane and high-stress affairs. An empowered employee typing commands manually pushed weeks of other people’s work, and often it Did Not Go Well.
Unfortunately, achieving business goals generally involves changing code.
The best coping strategy I’m aware of is to change code as frequently as possible.
I believe deploys should be routine, cheap, and safe. That is the philosophy we’ve used to build Skyliner, and we built Skyliner with the intent of sharing this philosophy with other teams.
Routine
In deployment, the path of least resistance should also be the right way to do it. It should be easier and quicker to deploy the right way than to circumvent the process. Making “proper” deploys more complex, slower, or riddled with manual steps backfires. Human nature will lead to chaotic evil, like hand-edited files on production machines.
I’ve been there. I have debugged more than one outage precipitated by live edits to php.ini. Our team worked hard in the years following those incidents to build a deployment system that was too easy and joyful to evade.
Cheap
Deploys can only be routine if they’re relatively quick. If it takes you hours to deploy your code, obviously this imposes a natural limit on how often deploys can be done. But the secondary effects of the latency are worse.
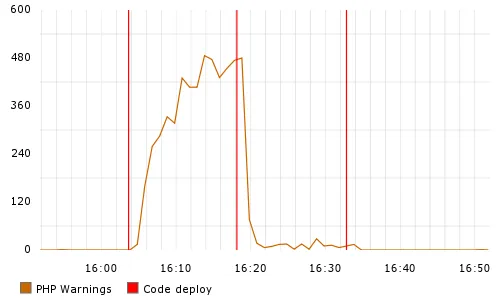
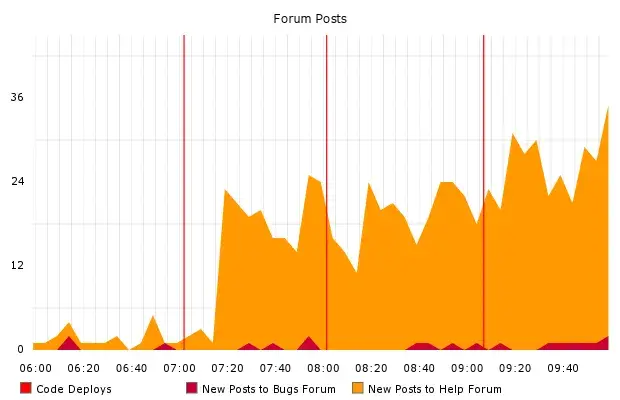
Rare, expensive deploys bundle many changes; quick, cheap deploys can bundle just a few. This becomes important when things don’t go as planned. The most plausible answer to “what went wrong” is usually “the last thing we changed.” So when debugging a problem in production, it matters a great deal whether the release diff is a handful of lines or thousands.
Many interesting things in the field of web operations immediately follow a code deploy. Here’s the record of me causing mass hysteria with several pushes, back in 2010.
Infrequent deploys also create natural deadlines. Engineers will tend to rush to get their changes in for a weekly push, and rushing leads to mistakes. If pushes happen hourly, the penalty for waiting for the next one to write a few more unit tests is much less severe.
Safe
Total safety in deploying code is not possible, and the deployment engine is only one part of the operational puzzle. Striving for a purely technical solution to deploy-driven outages is bound to lead to complexity that will have the opposite effect. As I’ve explained, I think that routine and cheap deploys are inherently safer, and these are cultural choices as much as they are a set of technical solutions.
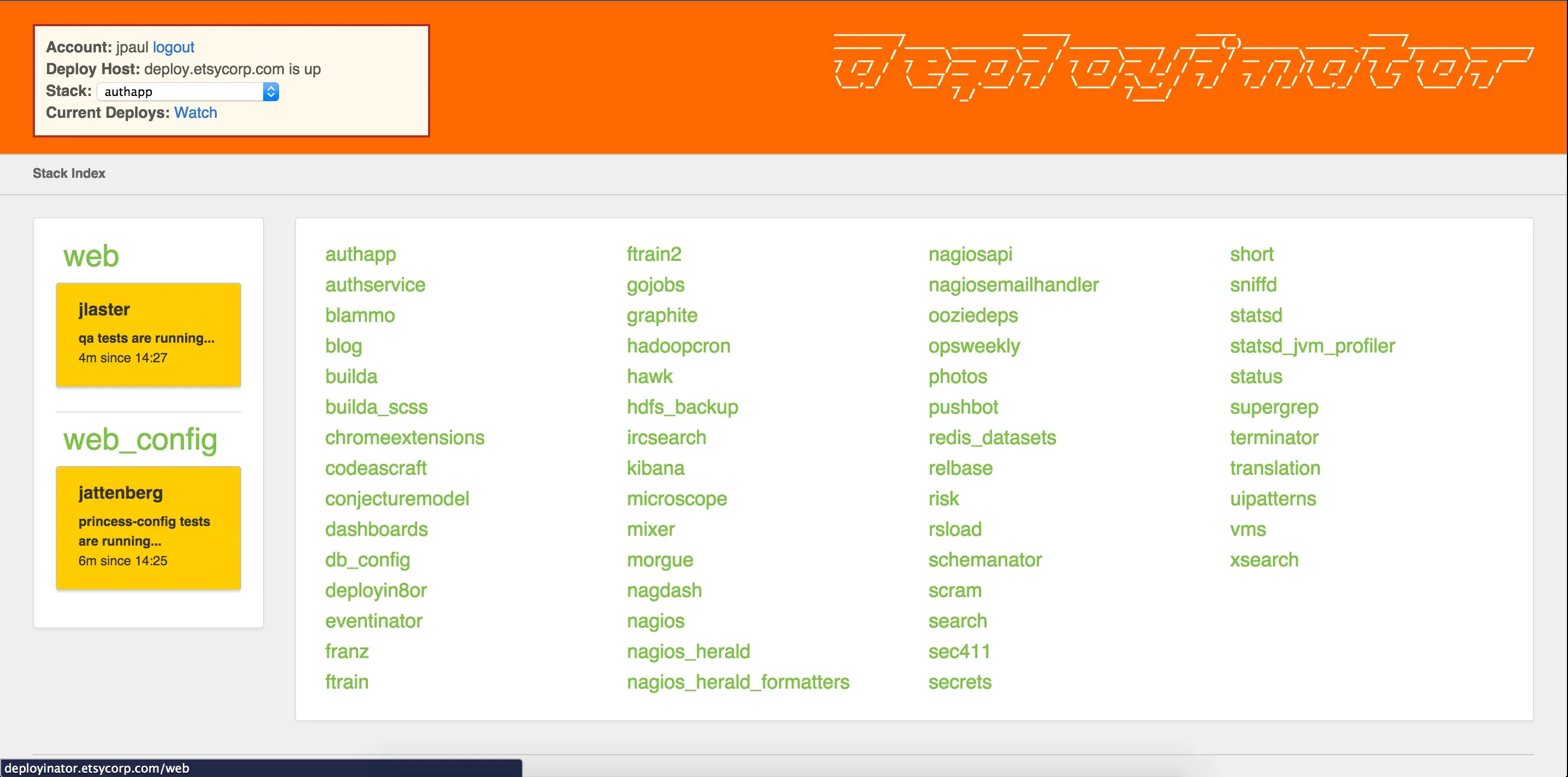
But, mechanics are still important. Early versions of Etsy’s Deployinator stopped pushing code if the browser of the person performing the deploy disconnected. That was a bad choice, and that became evident immediately the first time I tried to deploy from an airplane somewhere over Kansas. That’s ridiculous, but many teams use a single machine to orchestrate deployments and just hope that it never dies in the act.
Etsy's Deployinator, an inspiration for much of the Skyliner deployment experience.
It is also nontrivial to replace code as it’s running. In the bad old days we’d just do deploys during maintenance windows, but that’s become untenable. In the 21st century we have to make changes to sites while they’re live, and getting this right is a challenge.
Baking Hard Lessons Into Skyliner
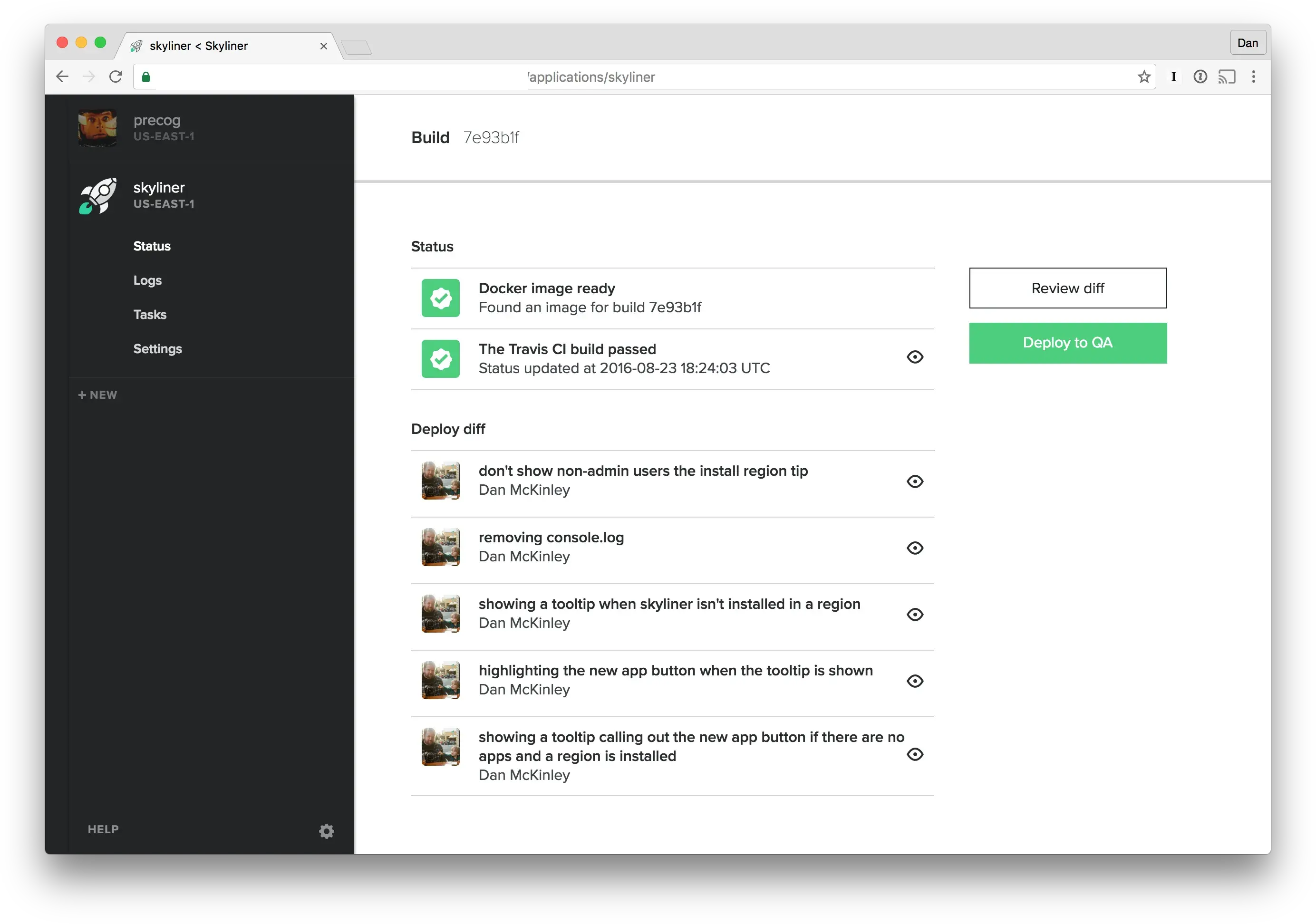
Skyliner deploys are easy to use: you just wait for the build to finish and press the button. They’re all logged and recorded, and it’d take significantly more effort to do anything less safe.
The deployment view in a Skyliner application.
We value simplicity, and are believers in Paul Hammond’s advice that you should always ship trunk. Skyliner affords you a single deployment branch. You’re free to act out baroque git contortions if you wish, but we suggest that you keep your release process simple and just deploy a master branch.
We’ve worked hard to make Skyliner deploys as fast as possible. The speed of deploys is decoupled from the instance count, so pushes to small clusters as well as large clusters can both be expected to finish in two or three minutes.
That’s not quite as fast as might be possible with a system that just copied files, but Skyliner deploys are much more than this. We think that the benefits are worth a minor amount of extra waiting.
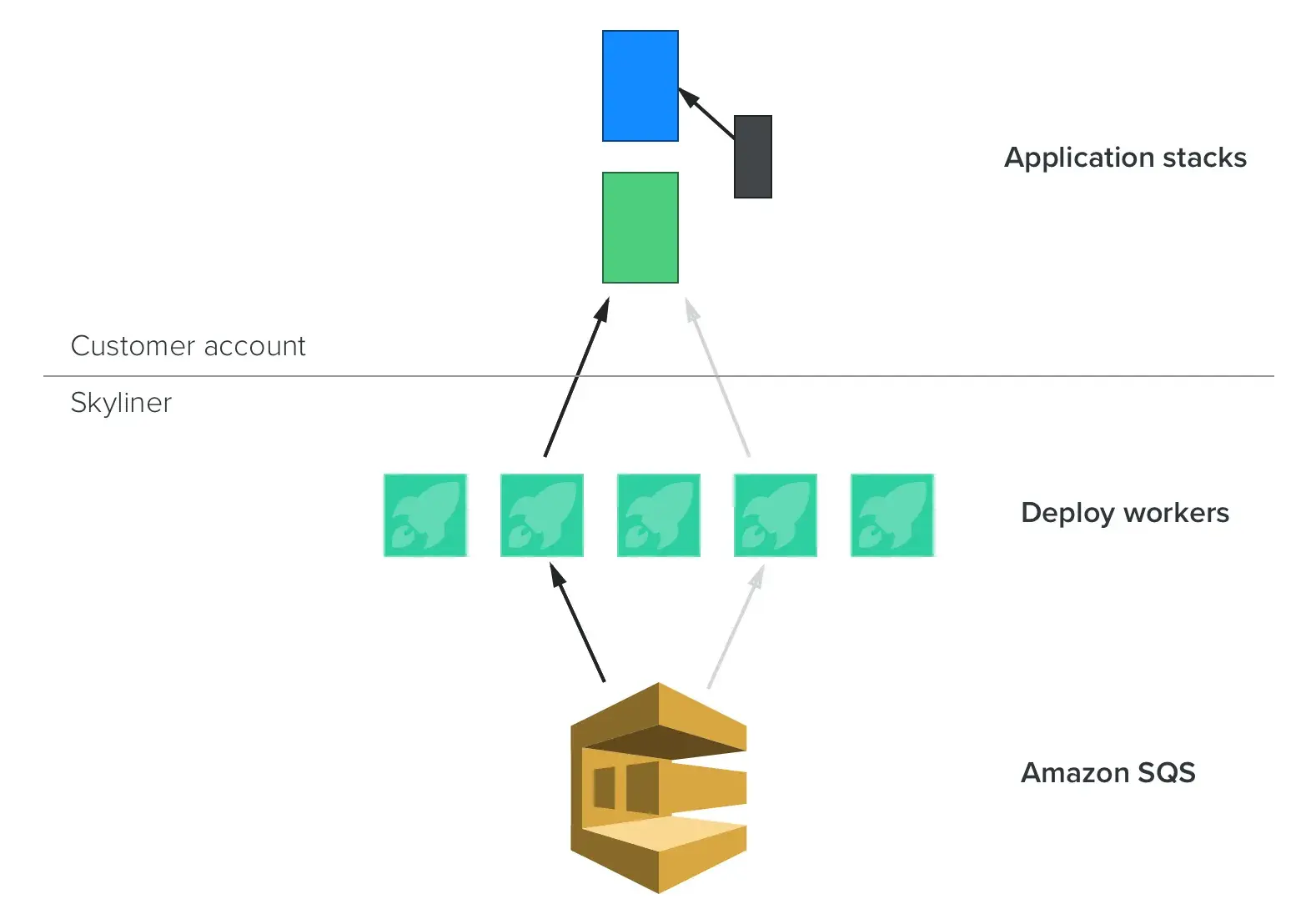
Our engine models each deploy as a finite state machine. Workers cooperate to complete (idempotent) tasks to advance the deploy state, which means that our instances can die without breaking running deploys.
The coordination of Skyliner deploys is distributed. Deploy workers advance a finite state machine, and can safely be killed without breaking a running deploy.
Every Skyliner deploy is a blue/green deploy. We spin up an entirely new cluster with the new code, make sure it’s healthy, and then make it live as an atomic switch at the load balancer level. This has a few notable advantages to deploying files in place:
Given a sufficiently good healthcheck, the system never makes a totally-broken version live. (Application bugs, regrettably, are still possible.)
Deployment is tricky business. We wanted to give Skyliner users a system informed by several decades of our own mistakes. “Well, that sucked,” I said to myself, “but there’s no reason that the rest of the world needs to trip over the same cord.”