Note: This was a post for Skyliner, which was a startup I co-founded in 2016. The post is recreated here since it makes some good points and was reasonably popular. But be advised the startup it describes is now defunct (we sold ourselves to Mailchimp in 2017).
I’ve been around long enough to see production releases done a few different ways.
My first tech job began back when delivering software over the internet wasn’t quite normal, yet. Deployments happened roughly every 12 to 18 months, and they were unmitigated disasters that stretched out for weeks.
When I got to Etsy in 2007, deploys happened a bit more often. But they were still arcane and high-stress affairs. An empowered employee typing commands manually pushed weeks of other people’s work, and often it Did Not Go Well.
But by the time I left Etsy in 2014, we were pushing code live to production dozens of times per day, with minimal drama. This experience has convinced me of a few things.
- Changing code is risky.
- Unfortunately, achieving business goals generally involves changing code.
- The best coping strategy I’m aware of is to change code as frequently as possible.
I believe deploys should be routine, cheap, and safe. That is the philosophy we’ve used to build Skyliner, and we built Skyliner with the intent of sharing this philosophy with other teams.
Routine
In deployment, the path of least resistance should also be the right way to do it. It should be easier and quicker to deploy the right way than to circumvent the process. Making “proper” deploys more complex, slower, or riddled with manual steps backfires. Human nature will lead to chaotic evil, like hand-edited files on production machines.
I’ve been there. I have debugged more than one outage precipitated by live edits to php.ini. Our team worked hard in the years following those incidents to build a deployment system that was too easy and joyful to evade.
Cheap
Deploys can only be routine if they’re relatively quick. If it takes you hours to deploy your code, obviously this imposes a natural limit on how often deploys can be done. But the secondary effects of the latency are worse.
Rare, expensive deploys bundle many changes; quick, cheap deploys can bundle just a few. This becomes important when things don’t go as planned. The most plausible answer to “what went wrong” is usually “the last thing we changed.” So when debugging a problem in production, it matters a great deal whether the release diff is a handful of lines or thousands.
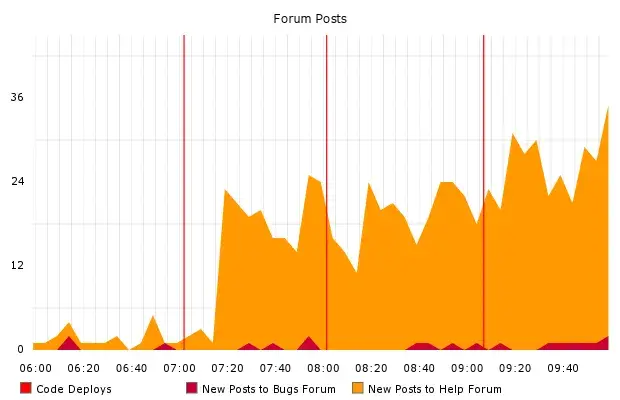
Infrequent deploys also create natural deadlines. Engineers will tend to rush to get their changes in for a weekly push, and rushing leads to mistakes. If pushes happen hourly, the penalty for waiting for the next one to write a few more unit tests is much less severe.
Safe
Total safety in deploying code is not possible, and the deployment engine is only one part of the operational puzzle. Striving for a purely technical solution to deploy-driven outages is bound to lead to complexity that will have the opposite effect. As I’ve explained, I think that routine and cheap deploys are inherently safer, and these are cultural choices as much as they are a set of technical solutions.
But, mechanics are still important. Early versions of Etsy’s Deployinator stopped pushing code if the browser of the person performing the deploy disconnected. That was a bad choice, and that became evident immediately the first time I tried to deploy from an airplane somewhere over Kansas. That’s ridiculous, but many teams use a single machine to orchestrate deployments and just hope that it never dies in the act.
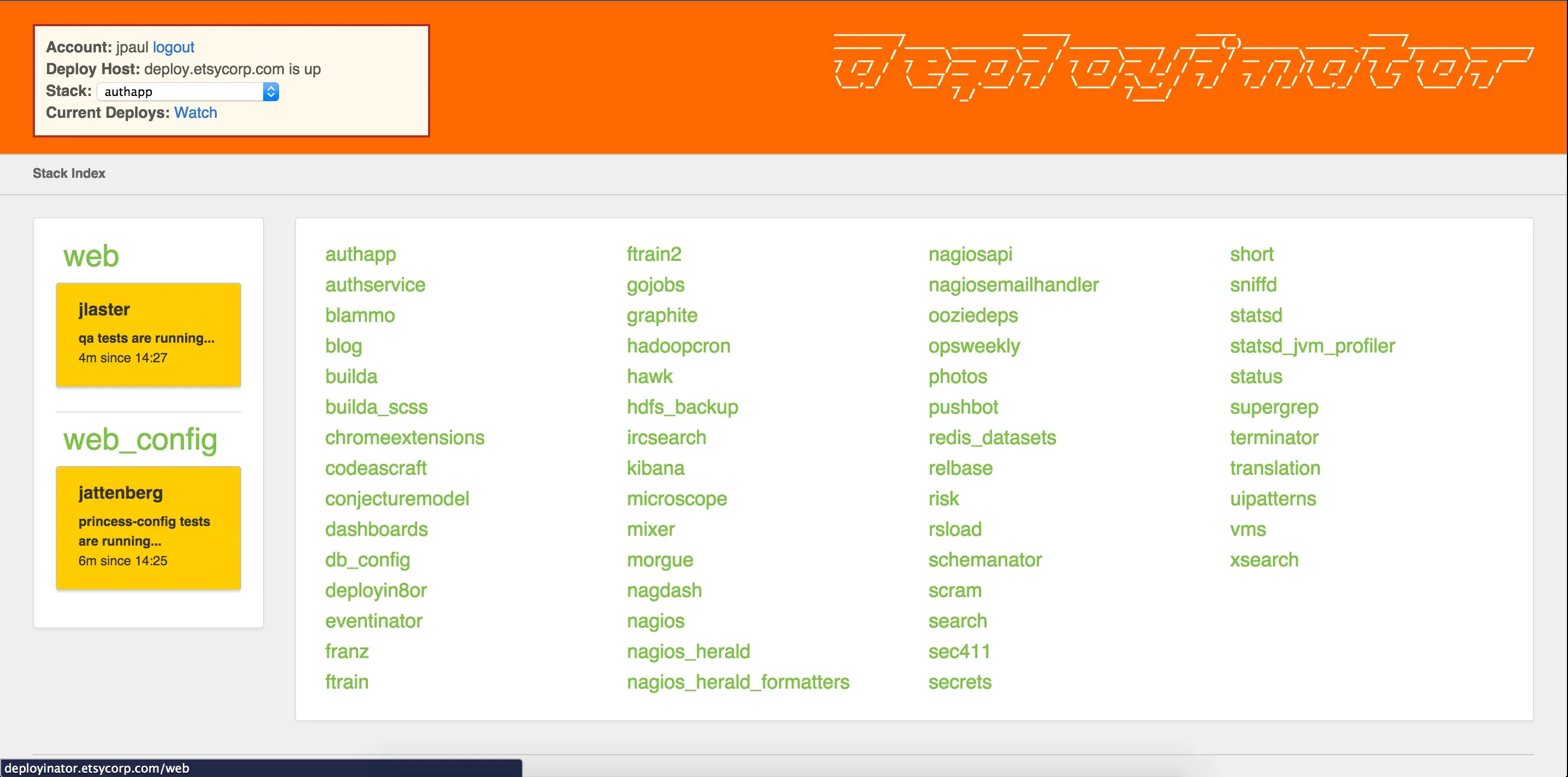
It is also nontrivial to replace code as it’s running. In the bad old days we’d just do deploys during maintenance windows, but that’s become untenable. In the 21st century we have to make changes to sites while they’re live, and getting this right is a challenge.
Baking Hard Lessons Into Skyliner
Skyliner deploys are easy to use: you just wait for the build to finish and press the button. They’re all logged and recorded, and it’d take significantly more effort to do anything less safe.
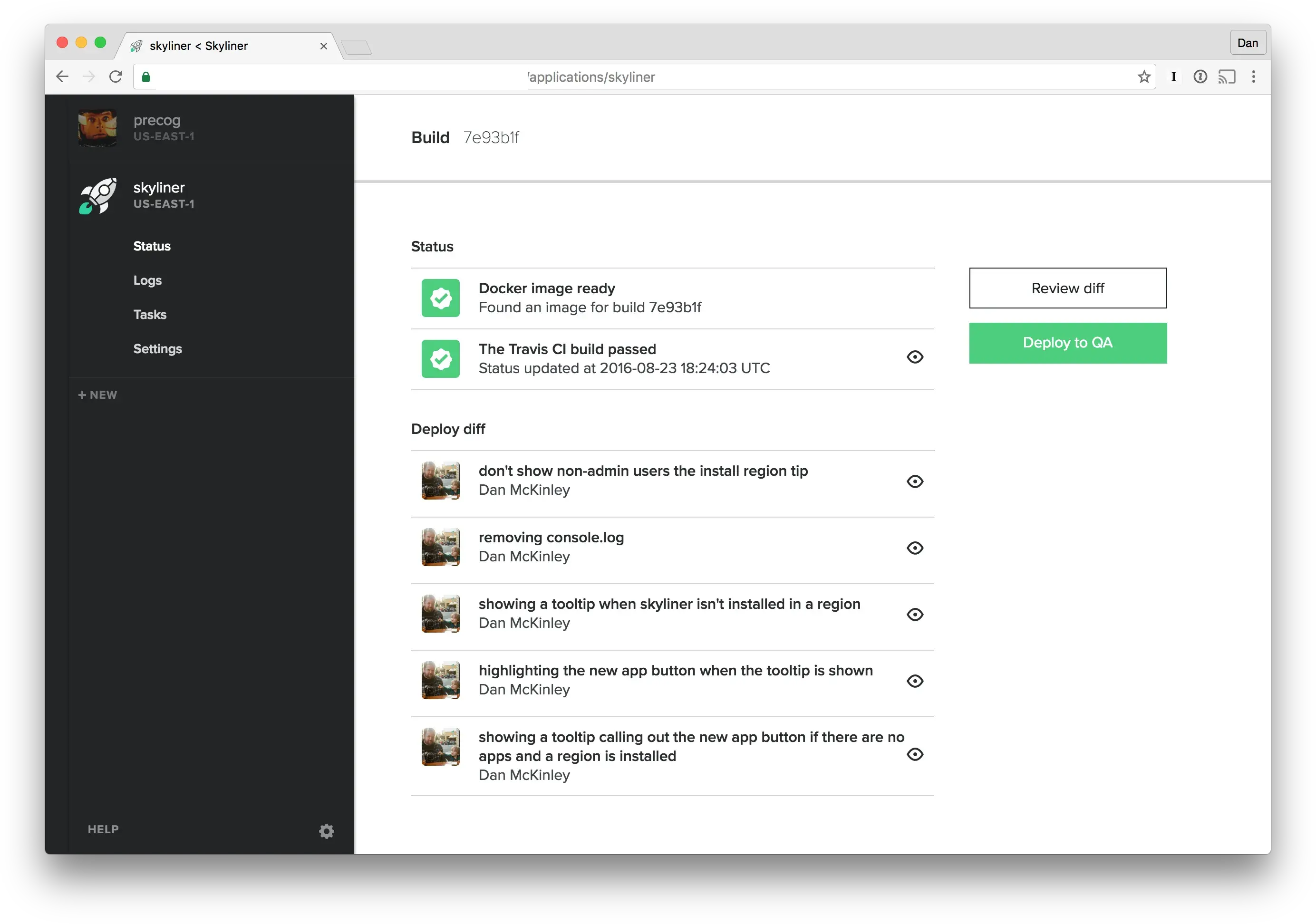
We value simplicity, and are believers in Paul Hammond’s advice that you should always ship trunk. Skyliner affords you a single deployment branch. You’re free to act out baroque git contortions if you wish, but we suggest that you keep your release process simple and just deploy a master branch.
We’ve worked hard to make Skyliner deploys as fast as possible. The speed of deploys is decoupled from the instance count, so pushes to small clusters as well as large clusters can both be expected to finish in two or three minutes.
That’s not quite as fast as might be possible with a system that just copied files, but Skyliner deploys are much more than this. We think that the benefits are worth a minor amount of extra waiting.
Our engine models each deploy as a finite state machine. Workers cooperate to complete (idempotent) tasks to advance the deploy state, which means that our instances can die without breaking running deploys.
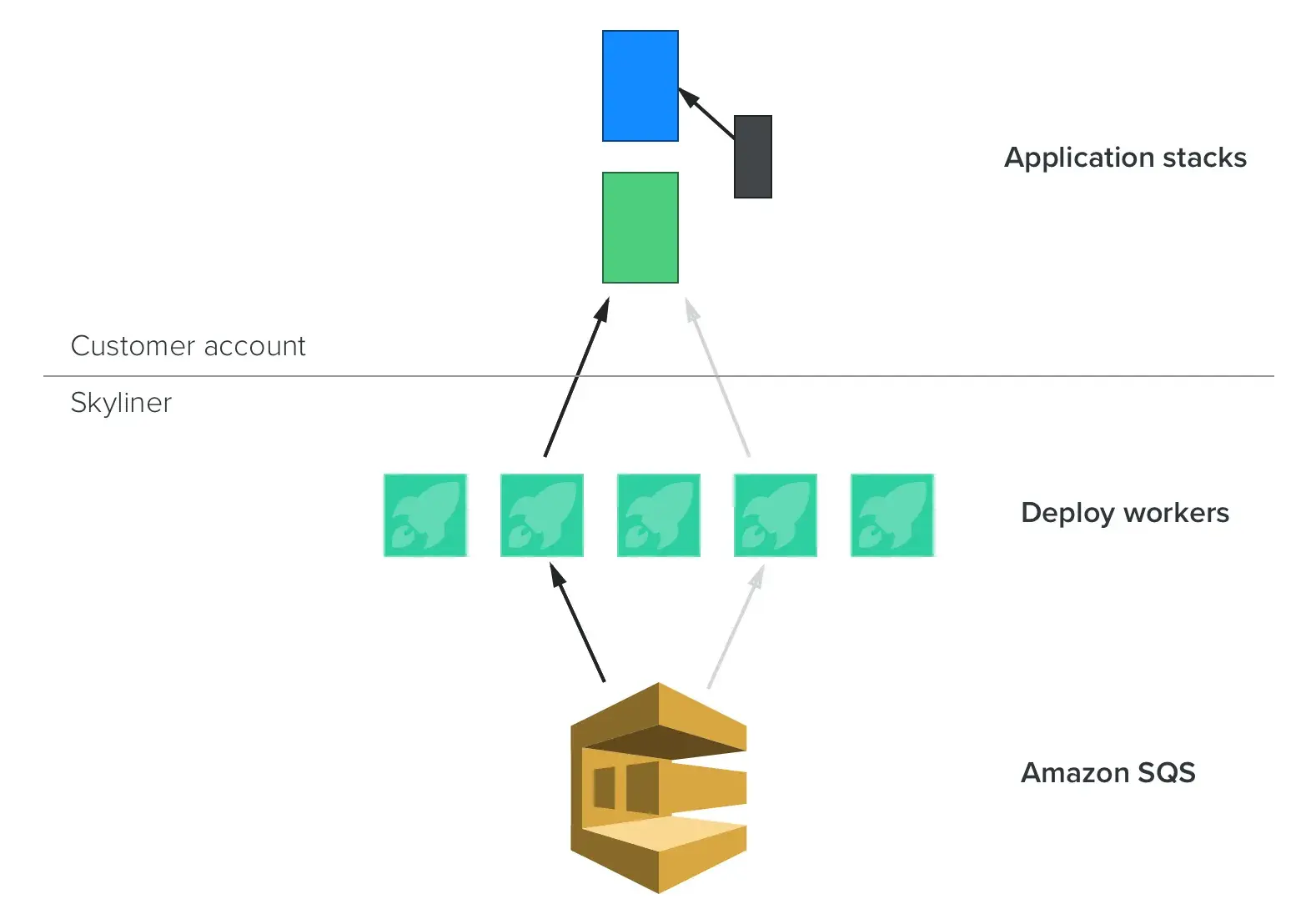
Every Skyliner deploy is a blue/green deploy. We spin up an entirely new cluster with the new code, make sure it’s healthy, and then make it live as an atomic switch at the load balancer level. This has a few notable advantages to deploying files in place:
- Given a sufficiently good healthcheck, the system never makes a totally-broken version live. (Application bugs, regrettably, are still possible.)
- By routinely destroying the entire cluster, we eliminate the possibility that the application has inadvertently become reliant upon local machine state.
My Gray Hairs, Grown For You
Deployment is tricky business. We wanted to give Skyliner users a system informed by several decades of our own mistakes. “Well, that sucked,” I said to myself, “but there’s no reason that the rest of the world needs to trip over the same cord.”