I recently read Co-Intelligence by Ethan Mollick. It was good! You should read it. I want to say this up front, since after some preamble I’m going to describe a Rube-Goldbergian attempt to poke petty holes in it. I don’t want the reader to lose sight of the big picture, which is that I was trying to do this in the spirit of the book. Which again, is pretty good.
The Zeitgeist is a-Polterin’
How are we going to know what’s true? How are we going to find information, now? It’s been on my mind lately, as it’s been on everyone else’s mind. The web has been thrown into chaos. As of right now if you ask Google if there’s a country in Africa that starts with “k,” you get a confident “no” that cites one post or another lampooning the entire debacle.
Google isn’t shooting itself in the face right before our eyes because they all think these results are good. (I bet the internal conversations are hilarious.) They’re shooting themselves in the face because they’re in a desperate steel cage match with the Innovator’s Dilemma. Our relationship with information retrieval seems like it’s changing, and this will affect Google. But as a participant in this shitshow they are constrained to seek the set of different equilibria that still more or less resemble web search. When they fuck up, they are fairly scrutinized in ways that their competitors are not. They have to transmogrify the golden goose into some sort of hovercraft, which is a significantly harder task than simply killing it.
LLM’s are now training on their own hallucinated content in a doom loop, and media companies are too busy dying [1] to be plausible as a solution to this. I don’t know what to say about Twitter except “good luck.” You’d be forgiven for hoping for the Nothing but Flowers scenario, in which we all collectively and abruptly decide to go back to the land.
But despite all of this I am not an LLM detractor. Whereas the entire web3 era came and went without ever coalescing into a legible concept of any kind, LLM’s are very much a non-fake technology. We haven’t figured out the right way to hold them, yet, but that’s no reason to just give up and walk into the sea.
Idk, Let’s All Read Books Instead?
When I’m really chewing on something I read books about it, and I recommend the practice. I do not recommend it as a solution to everything, as books are not necessarily written by humans and even when they are they are not necessarily using their whole ass to do it. But as a way to let ideas really stretch out in your mind and stink up the place, I don’t have a better way. So again, I read Co-Intelligence. And again, it was pretty good.
Inspiration struck right on schedule when my friend Peter Seibel also read Co-Intelligence. Peter noticed a claim about 3/4 of the way through:
[R]epeated studies found that differences between the programmers in the top 75th percentile and those in the bottom 25th percentile can be as much as 27 times along some dimensions of programming quality... [b]ut AI may change all that. [2]
Peter is a programming book author, and tech industry veteran turned high school CS teacher. You could say he’s dedicated himself to spreading the craft, and so this claim is something of a pet issue of his.

Indeed the claim is a well-established industry trope at this point. It is widely considered to be thinly sourced at best, and entirely vibes at worst. It usually relies on scant evidence when it’s sourced at all. But in this case, it was sourced! In a paper we hadn’t heard of before! The specific citation was:
The gap between the programmers: L. Prechelt, “An Empirical Comparison of Seven Programming Languages,” IEEE Computer 33, no. 10 (2000): 23–29, https://doi.org/10.1109/2.876288.
So I decided to dig in and see if the paper supported this [3].
No, The Cited Paper does not Support the Existence of 27x Programmers
Prechelt’s paper is a comparison of programming languages, not programmers. Its conclusion is closer to “C++ sucks” [4] than anything to do with programmer ability. There are two overlapping problems with using it here:
- The paper acknowledges weaknesses in its samples, and other reasons we may be looking at biased results. (This is lovely to see.)
- The paper is not trying to make any points about programmer capabilities.
Hence the conclusions of the paper don’t really support the premise in that part of Mollick’s text.
Again, I Have to Stress that Co-Intelligence is a Good Book
Co-Intelligence has sources that we are invited to check, and of course many books do not do this. Mollick is a serious person who is trying to do a good job, in good faith, and many are not. There’s nothing unusual about noticing a problem like this in a book. This is just what it’s like to read something that touches on topics that you happen to know a great deal about.
Many of 2024’s gravest epistemological dangers arise when we read things that we don’t know much about [5]. In those situations, we’re liable to reinforce our own biases or blithely accept the authority of the text. How can we do better?
The answer is probably something like “critical thinking,” or “close reading.” We should be putting more thought into the sources of what we’re consuming. We should be questioning whether those sources support the conclusions drawn, and what problems they may have themselves. By doing so we can form a more nuanced interpretation of what we’re consuming.
Of course, the downside is that this all takes a metric shit-ton of time.
What to do? Mechanize!
It occurred to me at this point that perhaps I could use AI to augment my critical thinking skills. It occurred to me because this is the sort of thing the book was constantly encouraging me to do:
Research has successfully demonstrated that it is possible to correctly determine the most promising directions in science by analyzing past papers with AI [6]
What if AI could be an asset in skepticism about itself? Could AI be both the cause of and solution to all of our filter bubble problems? I am not sure. Let’s find out!
My first few naive attempts were to simply feed the LLM [7] some content by hand. I’d give it a PDF, a passage from the book, and the specific claim that was being supported by the citation. I’d ask it what it thought, either in general or as a two parter (“How would you rate this paper? Do you think it provides good support for this claim in this text?”).
The results of this were disappointing–the LLM universally responded with paragraphs amounting to “yeah, lookin’ good hoss!” Being at least vaguely on top of the conversations around using LLM’s in anger, I figured that the problem here was that I was asking it to do far too much at once.
Revising the Approach
After thinking about it a bit more, I realized that the goal should probably be about prioritization. This is also in line with Mollick’s advice:
The closer we move to a world of Cyborgs and Centaurs in which the AI augments our work, the more we need to maintain and nurture human expertise. We need expert humans in the loop. [8]
I am definitely not going to check the 90+ academic papers cited by this book, let alone the web pages and other books cited. And on the basis of its output so far, I am also not going to just trust the LLM to do that for me without help. Instead, the goal would be to use AI to get the drudgery of sifting through references out of my way. I decided that I’d try this instead:
- I’ll ask the LLM to give each of the cited papers an overall trustworthiness score.
- I’ll ask the LLM to rate how well each citation supports the claim in the text.
- From those two scores, I’ll make a weighted list of things to dig into by hand, leveraging my own abilities better.
I spent a day day collecting the papers, and managed to find nearly all of them without having to pay a wall.
Scoring Papers
My first attempt at scoring the papers was direct: I just fed the LLM the paper and asked it to rate its trustworthiness on a scale of one to ten. The LLM scored nearly every paper a 9 or a 10 out of 10. That’s perhaps unsurprising, since there are several sources of selection combining to bias the book towards citing papers that aren’t just total nonsense [9]. But unfortunately that’s useless as a means to differentiate. Asking the same question while providing a sample of other papers as a basis for comparison produced the same results [10].
I switched to asking the LLM to stack rank a set of papers. I’d give it a paper with nine others, and ask it to give me the ranking of trustworthiness. At first this seemed to produce better results, meaning the LLM would relent and say, “ok, this paper is a four out of ten in this set.” But repeating this a few times showed that the rankings were unstable - the same paper would get a range of rankings between 1 and 10 that seemed quite broad.
It occurred to me that the instability might average out in a useful way with repeated trials. If we ask the LLM to repeatedly stack rank a paper, it might occasionally rate it as an 8 but ultimately average it as a 3. Like so:
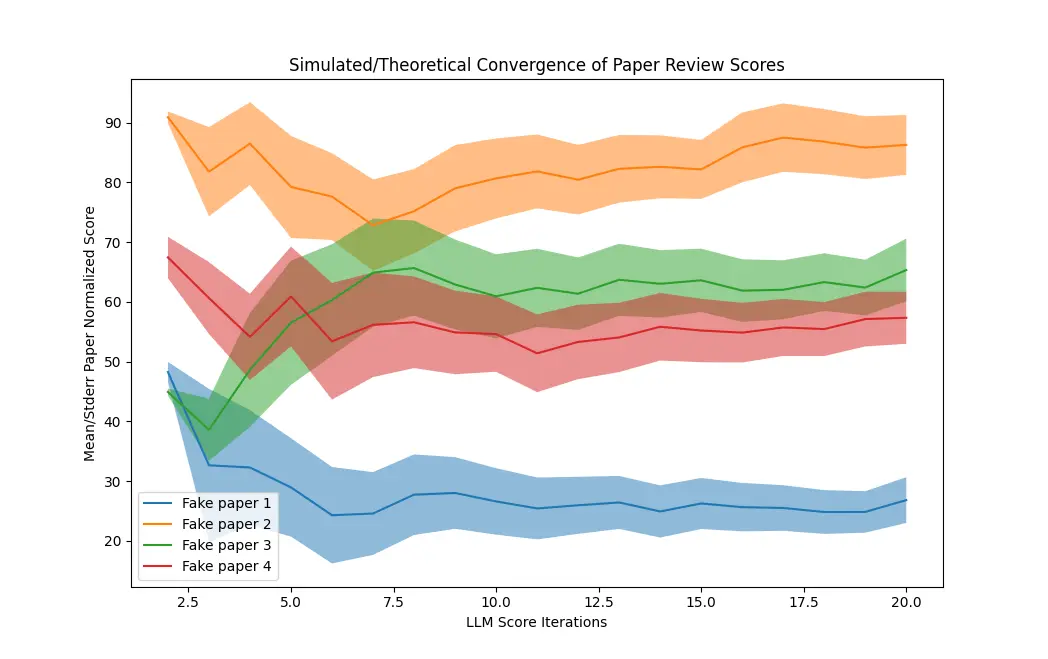
But after doing this 20 times for a set of referenced papers, in practice that didn’t work:
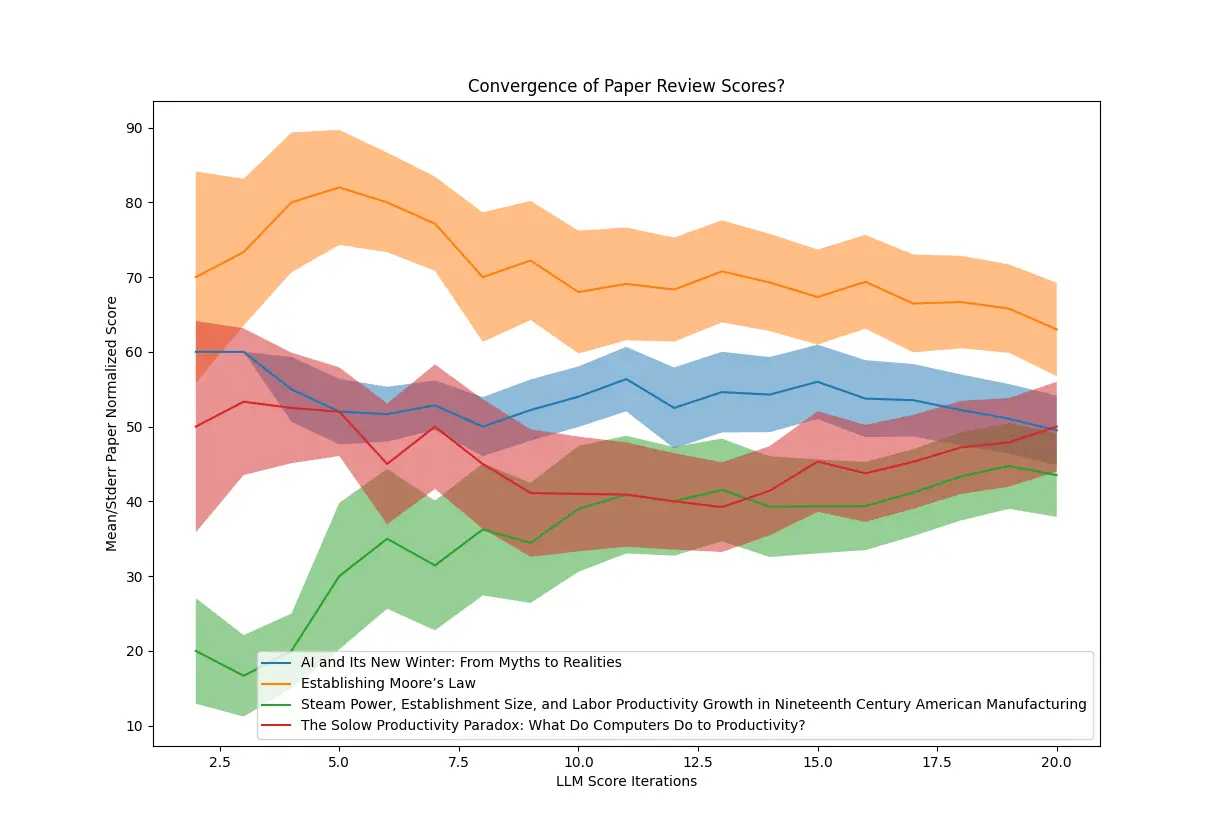
I redid the process one more time by asking the LLM to focus on just critiques of the papers. That produced much more pessimism, but not in a way that would give me a principled smaller set of papers to scrutinize by hand:
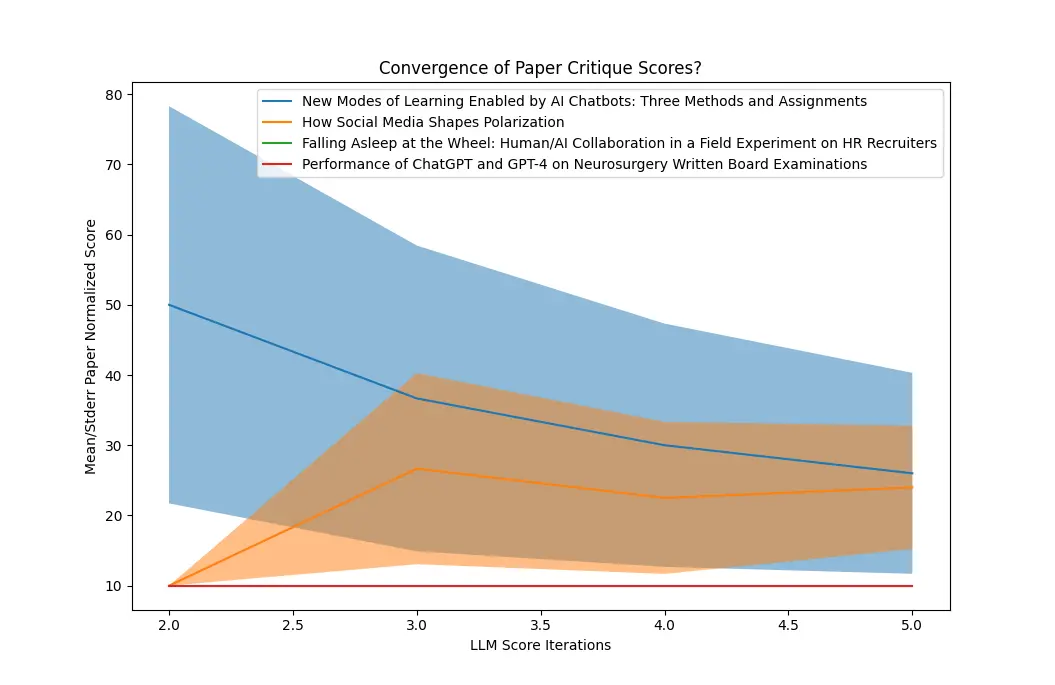
So progress seemed to stall out here. Having failed to find a way to give a paper a trustworthiness score that made any sense, it didn’t seem worthwhile to work out a way to rate the faithfulness of the citations to paper conclusions.
What Did We Learn?
The premise here was that I could write some AI automation to help me walk away from an overall good work with a more nuanced view than I otherwise would have. Given the correlated nature of the attempt and the subject matter, that definitely worked! I have a more nuanced view of what someone could reasonably ask a current LLM to do now! But it is not clear that I achieved anything durable yet, beyond building a very inefficient shuffle algorithm that cost me $100 and ate a few days.
I approached this with some classical ML system expertise, and therefore applied at least a little statistical thinking to what I did. I think in a lot of applications, folks just wouldn’t do this. The path of least resistance would be to ask the LLM for opinions, observe that it gives them, and plow forward.

This could be good or bad! In purely creative scenarios it’s probably a win. But it’d be a convoluted way to reinforce confirmation bias in others, i.e., the exact opposite of what I was trying to accomplish.
It seems like you could certainly use a current LLM to distinguish sources that are intrinsically terrible. But they aren’t particularly good at drawing out this kind of nuance right now, at least not in any straightforward way.
Hi, thank you for reading. If you liked this you might like some of my talks such as the notable banger Choose Boring Technology or maybe some of my other writing. To old friends, I apologize for not writing in a while. I assure you I was embroiled in some really baroque psychodrama that seemed important at the time.
Thanks to Camille Fournier, Peter Seibel, Lonnen, Moishe Lettvin, et al for help with this!
-
Here's where I thought I might link you to a great and relevant Search Engine episode about the media apocalypse, except as far as I can tell we've all decided to break the ability to link to podcast episodes. Case in point. Regardless, you should consider subscribing to Search Engine. ↥
-
Ethan Mollick, Co-Intelligence (New York: Penguin Random House, 2024), 156. ↥
-
Peter would like it to be noted that he reviewed the Prechelt paper himself, quickly concluded that it didn't support the book's claim, and moved on. The reader is encouraged to come to their own conclusions about our differing priority preferences and life choices. ↥
-
It's unclear if this needs to be empirically proven, but it is correct. The paper does this:
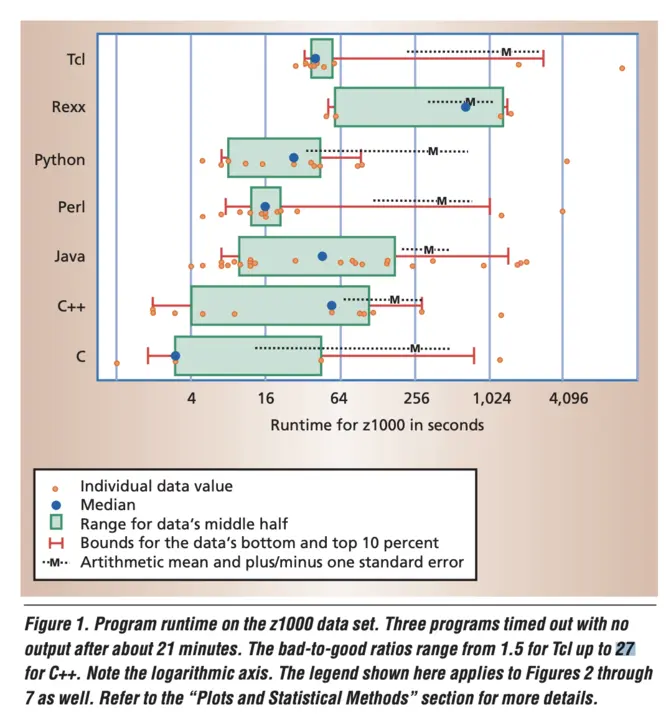
Prechelt studies a big set of programs written in different languages. He contrives a "bad to good ratio," which is the median of the slowest half of the programs divided by the median of the fastest half. The difference of "27 times" is the spread of outcomes within a language, which the book then conflates with programmer capability.
The paper talks a bit about how the programs in different languages are sourced from different places. The C++ programs are from CS master students, the Tcl programs are from open calls, etc. The paper discusses how there will be bias in the outcomes as the result of this. ↥
-
An example that's close to home for me is that some of my college friends (who also completed an ivy league engineering program) are now moon landing deniers. This seems to be the result of choosing the Joe Rogan podcast as a source of information and identity.
I don't actually know since I won't listen to it, but as far as I can discern this podcast is a decades-long freefall into the bottomless abyss of nonsense that yawns beyond the boundaries of one's own expertise. He had an actor on who thinks 1×1=2, and apparently took it seriously. That may be an extreme example, but we'd be mistaken to believe we're categorically immune from these kinds of errors just because we aren't megadosing shark cartilage and suffering head trauma regularly, or whatever.
Incidentally, do not contact me to discuss Joe Rogan. ↥
-
Mollick, 202. The paper he is citing in this case is not using a large language model, but is cool work regardless. They built their own semantic graph of research topics with more mundane extraction techniques, and then tried to predict future edges in it. They found that models with hand-crafted features outperformed unsupervised approaches, including a transformer model. And "[s]urprisingly, using purely network theoretical features without machine learning works competitively." But, this was all in 2022. ↥
-
Everything in this writeup was done with GPT-4o. ↥
-
Mollick, 182. ↥
-
Indeed if you ask it to read a very bad paper, it will rate its trustworthiness very low. ↥
-
Various attempts at excoriating the LLM to behave differently didn't get me anywhere either. "Your rankings overall should be normally distributed! Your mean ranking should be a five! Don't worry about your rankings getting back to the authors! Nobody is going to judge you for this!" ↥