For four months ending in early 2011, I worked on team of six to redesign Etsy’s homepage. I don’t want to overstate the weight of this in the grand scheme of things, but hopes flew high. The new version was to look something like this:
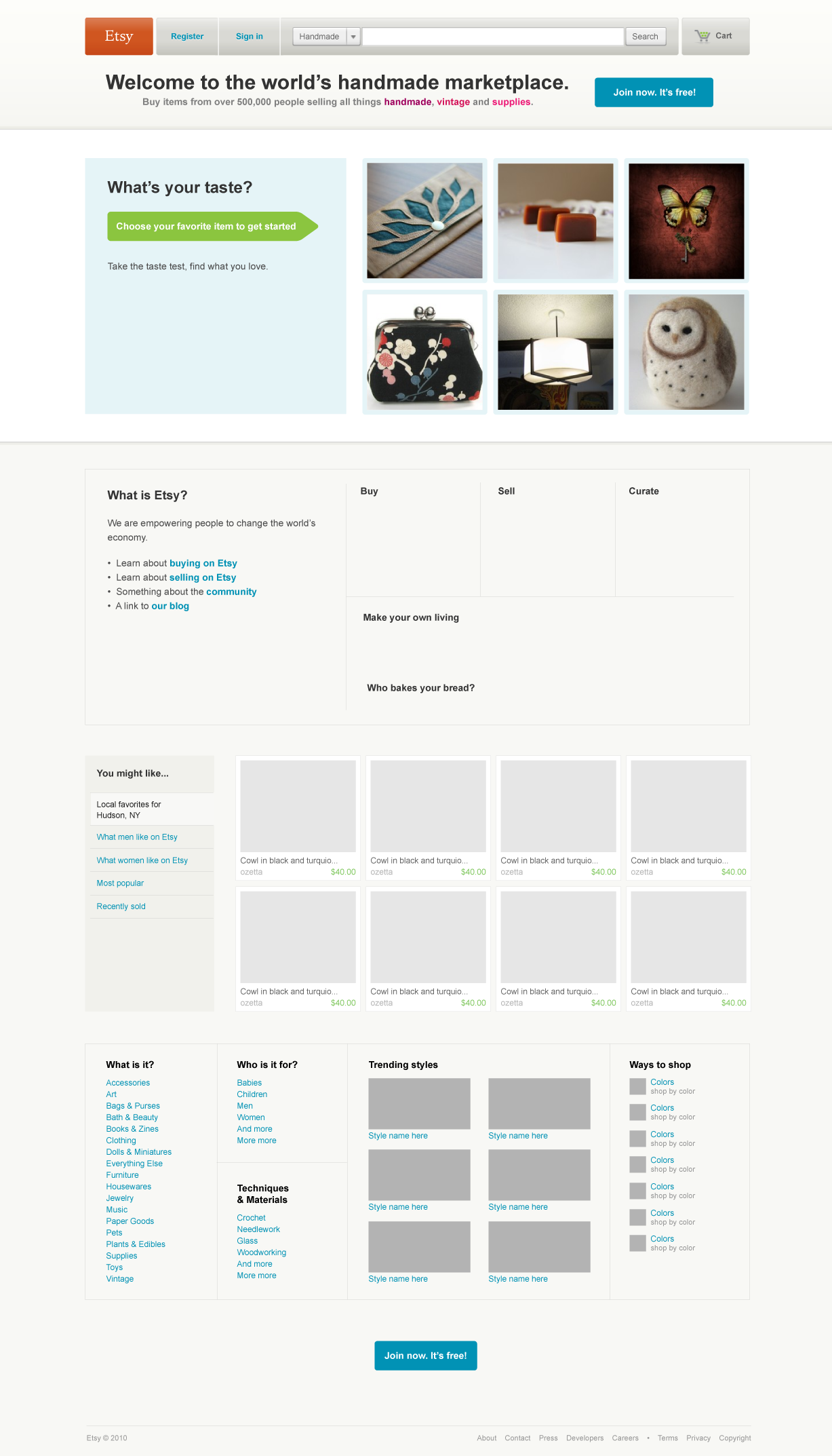
There were a number of methodological problems with this, one of our very first web experiments. Our statistics muscles were out of practice, and we had a very difficult time fighting the forces of darkness who wanted to enact radical redesigns after five minutes of real-time data. We had no toolchain for running experiments to speak of. The nascent analytics pipeline jobs failed every single night.
But perhaps worst of all, we publicized the experiment. Well, “publicized” does not accurately convey the magnitude of what we did. We allowed visitors to join the treatment group using a magic URL. We proactively told our most engaged users about this. We tweeted the magic URL from the @Etsy account, which at that point had well over a million followers.
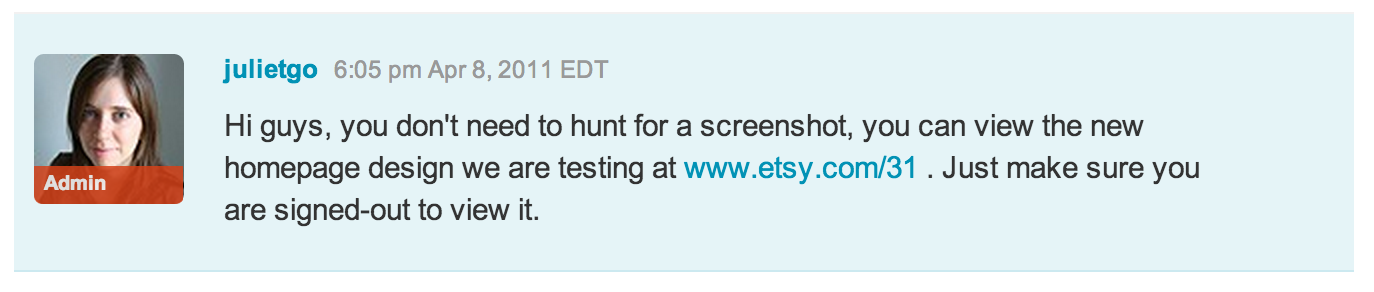
This project was a disaster for many reasons. Nearly all of the core hypotheses turned out to be completely wrong. The work was thrown out as a total loss. Everyone involved learned valuable life lessons. I am here today to elaborate on one of these: telling users about the experiment as it was running was a big mistake.
The Diamond-Forging Pressure to Disclose Experiments
If you operate a website with an active community, and you do A/B testing, you might feel some pressure to disclose your work. And this seems like a proper thing to do, if your users are invested in your site in any serious way. They may notice anyway, and the most common reaction to change on a beloved site tends to be varying degrees of panic.

As an honest administrator, your wish is to reassure your community that you have their best interest at heart. Transparency is the best policy!
Except in this case. I think there’s a strong argument to be made against announcing the details of active experiments. It turns out to be easier for motivated users to overturn your experiment than you may believe. And disclosing experiments is work, and work that comes before real data should be minimized.
Online Protests: Not Necessarily A Waste of Time
A fundamental reason that you should not publicize your A/B tests is that this can introduce bias that can affect your measurements. This can even overturn your results. There are many different ways for this to play out.
Most directly, motivated users can just perform positive actions on the site if they believe that they are in their preferred experiment bucket. Even if the control and treatment groups are very large, the number of people completing a goal metric (such as purchasing) may be just a fraction of that. And the anticipated difference between any two treatments might be slight. It’s not hard to imagine how a small group of people could determine an outcome if they knew exactly what to do.
| Group | Visits | Conversions (organic) | Conversions (gamed) | Proportion |
|---|---|---|---|---|
| Control | 10000 | 50 | 10 | 0.0060 |
| New | 10000 | 55 | 0 | 0.0055 |
| Control | New |
|---|---|
| 10000 visits | 10000 visits |
| 50 organic conversions | 50 organic conversions |
| 10 gamed conversions | 0 gamed conversions |
| 0.60% converted | 0.55% converted |
As the scope and details of an experiment become more fully understood, this gets easier to accomplish. But intentional, organized action is not the only possible source of bias.
Even if users have no preference as to which version of a feature wins, some will still be curious. If you announce an experiment, visitors will engage with the feature immediately who otherwise would have stayed away. This well-intentioned interest could ironically make a winning feature appear to be a loss. Here’s an illustration of what that looks like.
| Group | Visits (oblivious) | Visits (rubbernecking) | Visits (total) | Conversions | Proportion |
|---|---|---|---|---|---|
| Control | 500 | 50 | 550 | 30 | 0.055 |
| New | 500 | 250 | 750 | 35 | 0.047 |
| Control | New |
|---|---|
| 500 oblivious visits | 500 oblivious visits |
| 50 rubbernecking visits | 250 rubbernecking visits |
| 550 total visits | 750 total visits |
| 30 conversions | 35 conversions |
| 5.5% converted | 4.7% converted |
These examples both involve the distortion of numbers on one side of an experiment, but many other scenarios are possible. Users may change their behavior in either group for no reason other than that they believe they are being measured.
Good experimental practice requires that you isolate the intended change as the sole variable being tested. To accomplish this, you randomly assign visitors the new treatment or the old, controlling for all other factors. Informing visitors that they’re part of an experiment places this central assumption in considerable jeopardy.
Predicting Bias is Hard
“But,” you might say, “most users aren’t paying attention to our communiqués.” You may think that you can announce experiments, and only a small group of the most engaged people will notice. This is very likely true. But as I have already shown, the behavior of a small group cannot be dismissed out of hand.
Obviously, this varies. There are experiments in which a vocal minority cannot possibly bias results. But determining if this is true for any given experiment in advance is a difficult task. There is roughly one way for an experiment to be conducted correctly, and there are an infinite number of ways for it to be screwed.
A/B tests are already complicated: bucketing, data collection, experimental design, experimental power, and analysis are all vulnerable to mistakes. From this point of view, “is it safe to talk about this?” is just another brittle moving part.
Communication Plans are Real Work
Something I have come to appreciate over the years is the role of product marketing. I have been involved in many releases for which the act of explaining and gaining acceptance for a new feature constituted the majority of the effort. Launches involve a lot more than pressing a deploy button. This is a big deal.
It also seems to be true that people who are skilled at this kind of work are hard to come by. You will be lucky to have a few of them, and this imposes limits on the number of major changes that you can make in any given year.
It makes excellent sense to avoid wasting this resource on quite-possibly-fleeting experiments. It will delay their deployment, steal cycles from launches for finished features, and it will do these things in the service of work that may never see the light of day!
Users will tend to view any experiment as presaging an imminent release, regardless of your intentions. Therefore, you will need to put together a relatively complete narrative explaining why the changes are positive at the outset. A “minimum viable announcement” probably won’t do. And you will need to execute this without the benefit of quantitative results to bolster your case.
Your Daily Reminder that Experiments Fail
Doing data-driven product work really does imply that you will not release changes that don’t meet some quantitative standard. In such an event you might tweak things and start over, or you might give up altogether. Announcing your running experiments is problematic given this reality.
Obviously, product costs will be compounded by communication costs. Every time you retool an experiment, you will have to bear the additional weight of updating your community. Adding marginal effort makes it more difficult for humans to behave rationally and objectively. We have a name for this well-known pathology: the sunk cost fallacy. We’ve put so much into this feature, we can’t just give up on it now.

Announcing experiments also has a way of raising the stakes. The prospect of backtracking with your users (and being perceived as admitting a mistake) only makes killing a bad feature less palatable. The last thing you need is additional temptation to delude yourself. You have plenty of this already. The danger of living in public is that it will turn a bad release that should be discarded into an inevitability.
Consistency and Expectations
Let’s say you’ve figured out workarounds for every issue I’ve raised so far. You are still going to want to run experiments that are not publicly declared.
Some experiments are inherently controversial or exploratory. It may be perfectly legitimate to try changes that you would never release to learn more about your site. Removing a dearly beloved feature temporarily for half of new registrations is a good example of this. By doing so, you can measure the effect of that feature on lifetime value, and make better decisions with your marketing budget.
Other experiments work only when they’re difficult to detect. Search ranking is a high-stakes arms race, and complete transparency can just make it easier for malicious users gain unfair advantages. It’s likely you’re going to want to run experiments on search ranking without disclosing them.
It would be malpractice to give users the expectation that they will always know the state of running experiments. They will not have the complete picture. Leading them to believe otherwise can do more harm to your relationship than just having a consistent policy of remaining silent until features are ready for release.
What can you share?
Sharing too much too soon can doom your A/B tests. But this doesn’t mean that you are doomed to be locked in a steel cage match with your user base over them.

You can do rigorous, well-controlled experiments and also announce features in advance of their release. You can give people time to acclimate to them. You can let users preview new functionality, and enable them at a slower pace. These practices all relate to how a feature is released, and they are not necessarily in conflict with how you decide which features should be released. It is important to decouple these concerns.
You can and should share information about completed experiments. “What happened in the A/B test” should be a regular feature of your release notes. If you really have determined that your new functionality performs better than what it replaces, your users should have this data.
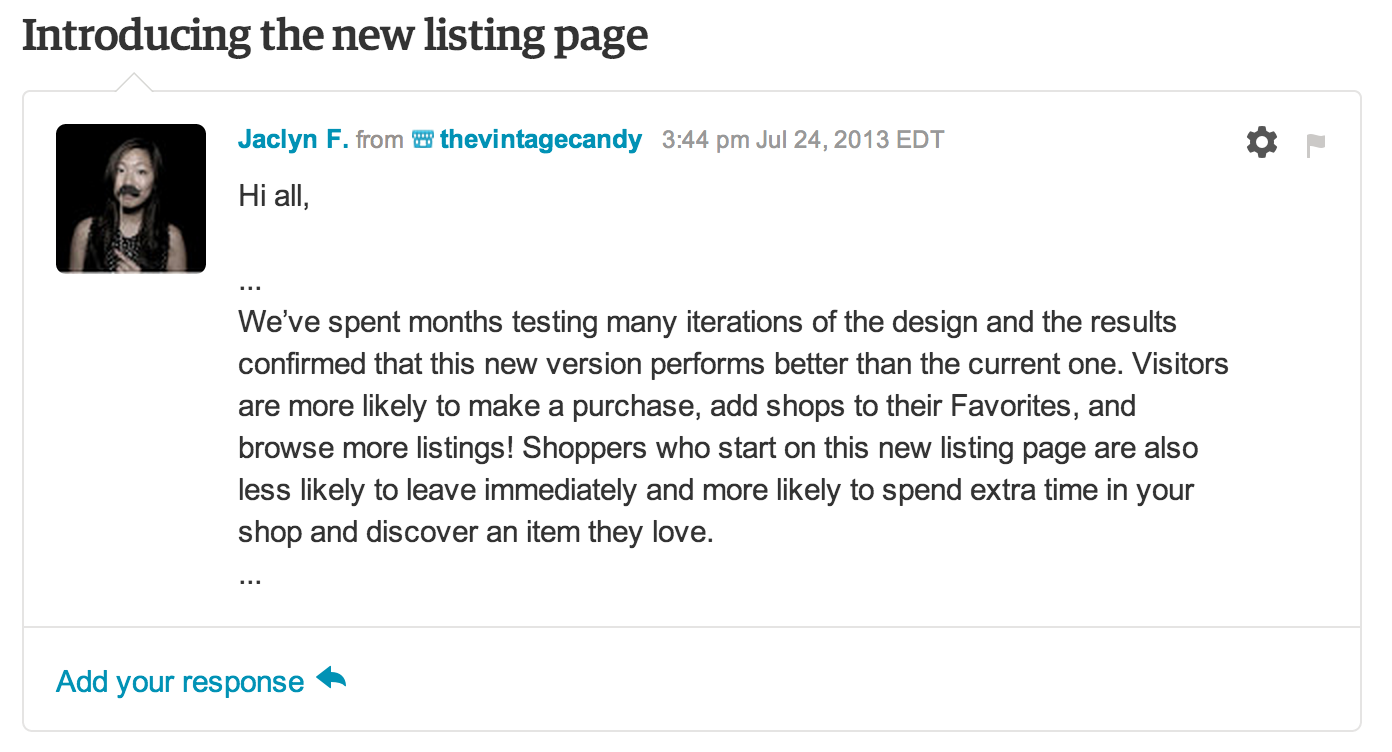
Counterintuitively, perhaps, trust is also improved by sharing the details of failed experiments. If you only tell users about your victories, they have no reason to believe that you are behaving objectively. Who’s to say that you aren’t just making up your numbers? Showing your scars (as I tried to do with my homepage story above) can serve as a powerful declaration against interest.
Successful Testing is Good Stewardship
Your job in product development, very broadly, is to make progress while striking a balance between short and long term concerns.
- Users should be as happy as possible in the short term.
- Your site should continue to exist in the long term.
The best interest of your users is ultimately served by making the correct changes to your product. Talking about experiments can break them, leading to both quantitative errors and mistakes of judgment.
I firmly believe that A/B tests in any organization should be as free, easy, and cheap as humanly possible. After all, running A/B tests is perhaps the only way to know that you’re making the right changes. Disclosing experiments as they are running is a policy that can alleviate some discontent in the short term. But the price of this is making experiments harder to run in the long term, and ultimately making it less likely that measurement will be done at all.
Thanks to Nell Thomas, Steve Mardenfeld, and Dr. Parker for their help on this.