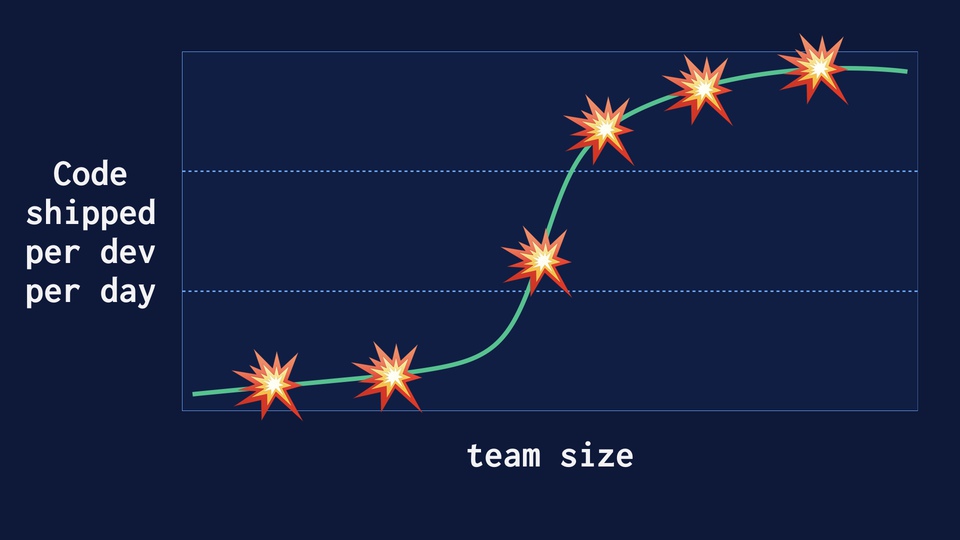
Ship Small Diffs The good lord would not have given me this 25 ton hydraulic splitter if I weren’t meant to cut up some logs.
THE .CLUB CLUB Once you get locked into a serious domain collection, the tendency is to push it as far as you can.